

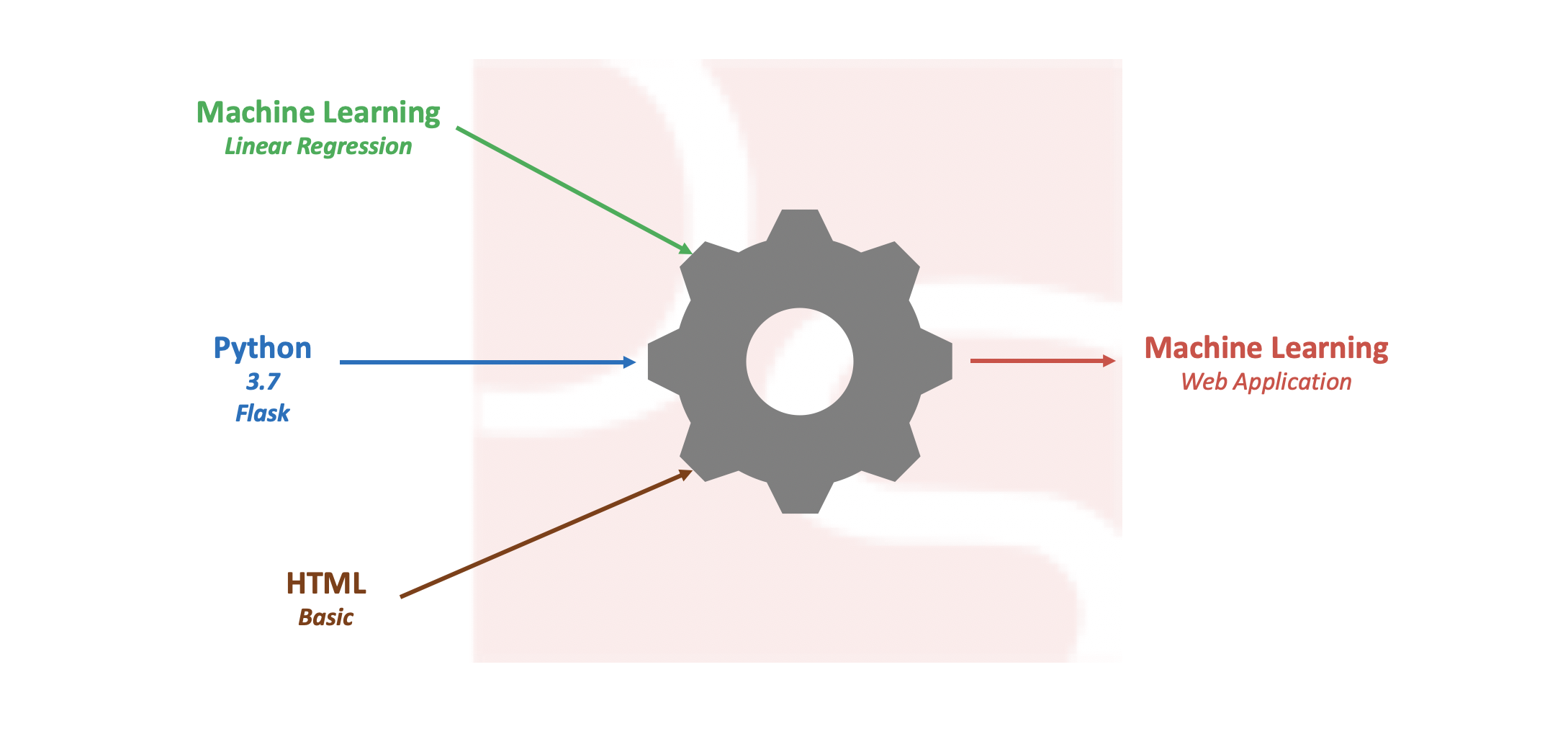
Build Simple Machine Learning Web Application using Python
Pre-processing data and developing efficient model on a given data set is one of the daily tasks of machine learning engineer with commonly used languages like Python or R. Not every machine learning engineer would get a chance or requirement to integrate the model into real time applications like web or mobile for end users […]
Ways to identify if data is Normally Distributed
Normal distribution also known as Gaussian distribution is one of the core probabilistic models to data scientists. Naturally occurring high volume data is approximated to follow normal distribution. According to Central limit theorem, large volume of data with multiple independent variables also assumed to follow normal distribution irrespective of their individual distributions. In reality we […]

Will highly correlated variables impact Linear Regression?
Linear regression is one of the basic and widely used machine learning algorithms in the area of data science and analytics for predictions. Data scientists will deal with huge dimensions of data and it will be quite challenging to build simplest linear model possible. In this process of building the model there are possibilities of […]
Will Oracle 18c impact DBA roles in the market?
There has been a serious concern in the market with announcement of Oracle Autonomous database 18c release. Should this be considered as a threat to Oracle DBA’s roles in the market? Let us gather facts available on the Oracle web to understand what exactly this is going to be and focus on skill improvements accordingly. […]

How Oracle database does instance recovery after failures?
INSTANCE RECOVERY – Oracle database have inherit feature of recovering from instance failures automatically. SMON is the background process which plays a key role in making this possible. Though this is an automatic process that runs after the instance faces a failure, it is very important for every DBA to understand how is it made […]

Why should we configure limits.conf for Oracle database?
Installing Oracle Database is a very common activity to every DBA. In this process, DBA would try to configure all the pre-requisites that Oracle installation document will guide, respective to the version and OS architecture. In which the very common configuration on UNIX platforms is setting up LIMITS.CONF file from /etc/security directory. But why should […]

Why RMAN needs REDO for Database Backups?
RMAN is one of the key important utility that every Oracle DBA is dependent on for regular day to day backup and restoration activities. It is proven to be the best utility for hot backups, in-consistent backups while database is running and processing user sessions. With all that known, as an Oracle DBA it will […]

Will huge Consistent Reads floods BUFFER CACHE?
Oracle Database BUFFER CACHE is one of the core important architectural memory component which holds the copies of data blocks read from datafiles. In my journey of Oracle DBA this memory component played major role in handling Performance Tuning issues. In this Blog, I will demonstrate a case study and analyze the behavior of BUFFER […]

Can a data BLOCK accommodate rows of distinct tables?
In Oracle database, data BLOCK is defined as the smallest storage unit in the data files. But, there are many more concepts run around the BLOCK architecture. One of them is to understand if a BLOCK can accommodate rows from distinct tables. In this article, we are going to arrive at the justifiable answer with […]

Can you really flush Oracle SHARED_POOL?
One of the major player in the SGA is SHARED_POOL, without which we can say that there are no query executions. During some performance tuning trials, you would have used ALTER SYSTEM command to flush out the contents in SHARED_POOL. Do you really know what exactly this command cleans out? As we know that internally […]
